It's time to finish it. First, we'll need some helper functions:
Code:
sum_log_cosh <- function(m) {
sum(log(cosh(m$residuals)))
}
gasinh <- function(x, xi = 0, lambda = 1) {
asinh((x - xi) / lambda)
}
gsinh <- function(x, xi = 0, lambda = 1) {
sinh(x) * lambda + xi
}
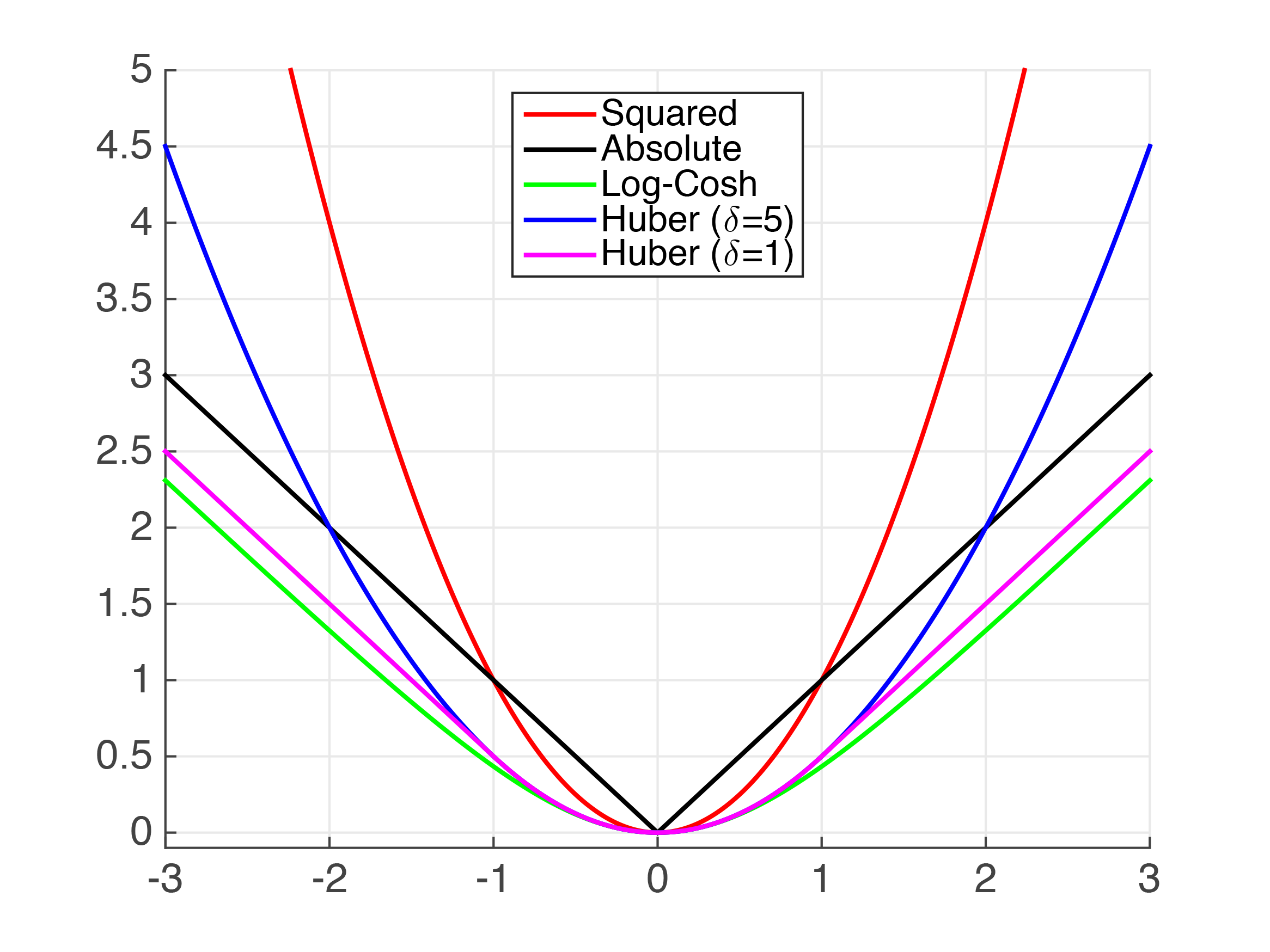
Above, we have the log-cosh loss function from earlier, then a generalized form of the asinh function and its inverse, sinh.
Why don't we have gamma and delta anymore? Well, this is because when we use a linear model, each variable has a coefficient associated with it that acts exactly like delta does. There is an additional coefficient (the Y-intercept) that essentially replaces all of the gammas into a single summation. So both of these parameters are redundant within the context of a linear model.
Now, onto the big kahuna:
Code:
lm.gat <- function(formula, data = NULL,
loss = sum_log_cosh,
iterations = 1, penalty = 1e-9,
verbose = FALSE) {
as.df <- as.data.frame
use.gasinh <- function(i, df, prm) {
gasinh(df[, i], prm[2 * (i - 1) + 1], prm[2 * (i - 1) + 2])
}
env <- if (is.null(data)) environment(formula) else as.environment(data)
sub <- as.df(sapply(all.vars(formula), get, envir = env))
n <- ncol(sub)
prm <- rep(c(0, 1), n)
evaluate <- function(prm) {
mut <- setNames(as.df(sapply(1:n, use.gasinh, sub, prm)), names(sub))
tryCatch({
m <- lm(formula, mut)
cost <- penalty * mean(prm ^ 2)
loss(m) + cost
}, error = function(e) {
Inf
})
}
for (k in 1:iterations) {
opt <- optim(prm, evaluate)
prm <- opt$par
if (verbose) {
message("Loss: ", format(opt$value, scientific = TRUE))
}
}
prm <- opt$par
mut <- setNames(as.df(sapply(1:n, use.gasinh, sub, prm)), names(sub))
m <- lm(formula, mut)
detransform <- function(y) gsinh(y, prm[1], prm[2])
list(detransform = detransform,
par = prm,
fit = m,
opt = opt,
df.sub = sub,
df.mut = mut,
z = detransform(m$fitted.values))
}
It's not exactly easy to explain this function - which isn't perfect, by the way. It will only well on continuous random variables and the transformation is applied to all variables in the model, so it's not very customizable. Essentially, for all variables including the response, we have an associated pair of parameters which transforms that variable in asinh space. These parameters are wiggled around by the optimizer, minimizing loss on the residuals. What's neat is that it can optimize interactive models as well.
Let me demonstrate. Let's say we are using the built-in `mtcars` dataset. We will try to predict quarter-mile time (`qsec`) by horsepower, miles per gallon, and weight (`hp`, `mpg`, `wt`) in a full interactive model:
Code:
summary(lm(qsec ~ hp * mpg * wt, mtcars))
# Call:
# lm(formula = qsec ~ hp * mpg * wt, data = mtcars)
# Residuals:
# Min 1Q Median 3Q Max
# -1.5219 -0.5882 -0.0978 0.4013 3.1959
# Coefficients:
# Estimate Std. Error t value Pr(>|t|)
# (Intercept) 14.0426771 10.9005197 1.288 0.210
# hp 0.0017784 0.0590665 0.030 0.976
# mpg 0.0249053 0.3921269 0.064 0.950
# wt 0.2427188 3.4981471 0.069 0.945
# hp:mpg -0.0005924 0.0026322 -0.225 0.824
# hp:wt 0.0016601 0.0179826 0.092 0.927
# mpg:wt 0.1050975 0.1451373 0.724 0.476
# hp:mpg:wt -0.0003813 0.0008658 -0.440 0.664
# Residual standard error: 1.102 on 24 degrees of freedom
# Multiple R-squared: 0.7055, Adjusted R-squared: 0.6196
# F-statistic: 8.215 on 7 and 24 DF, p-value: 4.052e-05
This is a simple approach using the original variable space, nothing is transformed. Notice the p-value is highly significant, but we only have an R-squared value of 70.5%, meaning that that amount of variation in the response variable is explained by our model. Furthermore, none of our coefficients are significant on their own, meaning this model is over-parameterized.
Let's try with our auto-transforming model:
Code:
summary(lm.gat(qsec ~ hp * mpg * wt, mtcars, iterations = 5)$fit)
# Call:
# stats::lm(formula = formula, data = mut)
# Residuals:
# Min 1Q Median 3Q Max
# -0.0025768 -0.0006795 0.0001064 0.0006047 0.0023484
# Coefficients:
# Estimate Std. Error t value Pr(>|t|)
# (Intercept) 1.986e+00 7.537e-04 2635.538 < 2e-16 ***
# hp 7.993e-04 1.277e-04 6.259 1.81e-06 ***
# mpg -8.981e-04 4.055e-04 -2.215 0.036518 *
# wt -5.751e-03 5.441e-04 -10.568 1.65e-10 ***
# hp:mpg 2.700e-04 5.836e-05 4.627 0.000107 ***
# hp:wt -2.916e-04 1.005e-04 -2.902 0.007821 **
# mpg:wt -1.725e-03 2.280e-04 -7.566 8.34e-08 ***
# hp:mpg:wt -1.658e-04 2.609e-05 -6.354 1.43e-06 ***
# ---
# Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
# Residual standard error: 0.001372 on 24 degrees of freedom
# Multiple R-squared: 0.9142, Adjusted R-squared: 0.8891
# F-statistic: 36.52 on 7 and 24 DF, p-value: 2.732e-11
The R-squared value shot up to 91.4%, so we've captured that much more variation in the response variable! Now all of the coefficients are significant, and the overall model p-value is extremely significant.
So what's going on? The optimizer seeks to linearize all of these relationships, all at once. Since log-cosh is a very robust yet precise loss function, this works pretty well.
We have a very small, understandable, machine learning program here. It works automatically with no need for a human to go in and determine the best transformation for each variable. It's robust because it uses a generalized unimodal distribution that accounts for centralization, dispersion, skewness, and kurtosis with minimal parameterization. All of the transformations and modeling are completely reversible, so the results and parameters can be understandable to a person, unlike "black-box" machine learning algorithms like deep learning where the weights eventually become meaningless.
It's not going to compete with the ML algorithms behind LLMs ever, but if you have smaller datasets and just want a model that can automatically transform distributions, try it out!








 Reply With Quote
Reply With Quote








Bookmarks